Building a Train Horn Detection Neural Network
Weekend project to detect train horn sounds from a computer microphone.
Chris Laan

I happen to live near a train, this train honks quite a bit throughout the day and night. Also, the train tracks cut through the neighborhood across five or six streets without any automatic gates to prevent crossing. So before the train can cross each street, it is required to blast the horn for a while. So as a therapeutic exercise I decided to try and detect and quantify the honking behavior. I was also hoping for a way to check in real-time if the train is blocking the street. It can be quite annoying if you're in a rush and get stuck behind the train. This post details my weekend project to do this.
TLDR;
After a weekend of hacking, I was able to get an accurate train horn detector running live from a mic outside my window. You can get the code to train the network on github.
I also post the detections live online here: BywaterTrain.com
Neural Network
I'm not familiar with audio classification, so I did some quick googling in the hope that someone else had solved a similar problem already. My constraints were that the model run fast enough to process live audio from the mic. Since I did not have a ton of labeled data, I was looking for an "ImageNet of audio" type of network I could fine tune on a very small dataset. Yamnet from google seemed to check a few of those boxes so I went with that.
Yamnet
From google: "YAMNet is a pretrained deep net that predicts 521 audio event classes based on the AudioSet-YouTube corpus, and employing the Mobilenet_v1 depthwise-separable convolution architecture." So the fact that it uses Mobilenet_v1 means it's probably fast enough, and being pre-trained on a large dataset is even better.
The AudioSet-YouTube dataset from google interesting on its own. Created from the audio within youtube clips, you can download it as .csv files that point to the time within the youtube video, or as a 128-bit feature vector as output by their VGG-style architecture ( see here ).
The dataset already contained various train related categories, but the accuracy it gave on my dataset was not good enough, so I decided to fine tune an additional network on top of the yamnet output.
If your data is one of the 521 classes, you might be able to directly use the yamnet output and not have to train anything at all.
Running predictions from the pre-trained yamnet model was very easy. The first step is checking out the tf models repo that contains it: https://github.com/tensorflow/models.
The repo contains a demo jupyter notebook to run the model on your own data, and visualize the results:
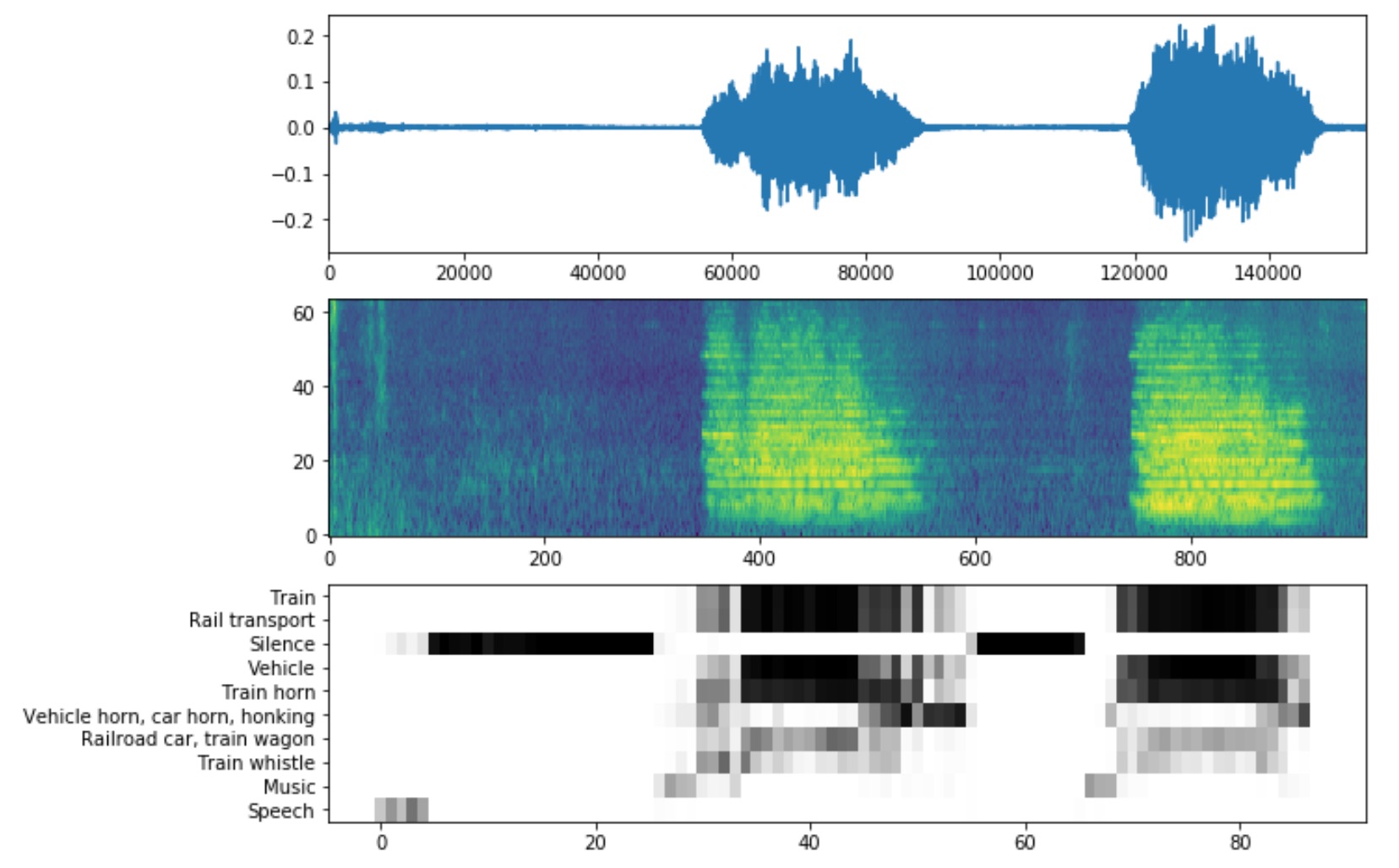
So out of the box the network correctly identifies a train horn in my sample data. But after trying some more difficult examples, I determined I would need to train on my own data. The sound coming in from the microphone outside of my window was a lot noisier with lower volume than the pristine train horn shown here.
Fine Tuning
My initial plan was to do a standard fine tuning network surgery and remove the top classification layer, replacing it with a fresh one sized for my two categories: "train horn" and "not train horn". But after going down this path for a few hours I got stuck on some data preprocessing/input shape/batching issues related to how the audio data is split into patches before being fed into yamnet. I'm sure this is a solvable problem, but in the interest of time I chose to directly grab the dense feature vector output from the layer below the classifier in the network, and train a separate network on those vectors. This approach avoided messing with yamnet's preprocessing pipeline; my new network just takes in a batch of (1024,1) features as output by yamnet. So, given a waveform, yamnet splits it into chunks, and converts each waveform into mel spectrogram representation before processing it. Each patch becomes a 1024 length vector, and is then run through the second model, which outputs a classification score for each category.
Data Prep
For my training data, I created a small dataset consisting of around 10 sounds for "train horn", and 10 for "background" or "not train". The "not train" category was pretty arbitrary; I just grabbed some sounds from https://freesound.org/; I focused on sounds that would probably occur outside my window: dogs barking, people talking, cars, etc. On top of that each training sample is augmented slightly by time stretching, adjusting volume, or adding noise.
In the sample code, I removed a 2-3 of the larger sound files. So the accuracy there will be slightly lower than what I got. You can experiment with how much data is required for your task.
Training only takes 30 seconds on my macbook, so it's easy to play with different architectures and hyperparameters. The results were good enough for my use case, so I moved on to classifying audio directly from the microphone.
Live Audio Classification
For live audio classification, I used the PyAudio library. With PyAudio you can load files, play them, and record from input devices. Here is a sample script to record a wav file from the mic:
"""PyAudio example: Record a few seconds of audio and save to a WAVE file."""
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 44100
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* recording")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
The (messy) script I ended up with is here: https://github.com/laanlabs/train_detector/blob/master/classify_from_mic.py
Pushing to the web
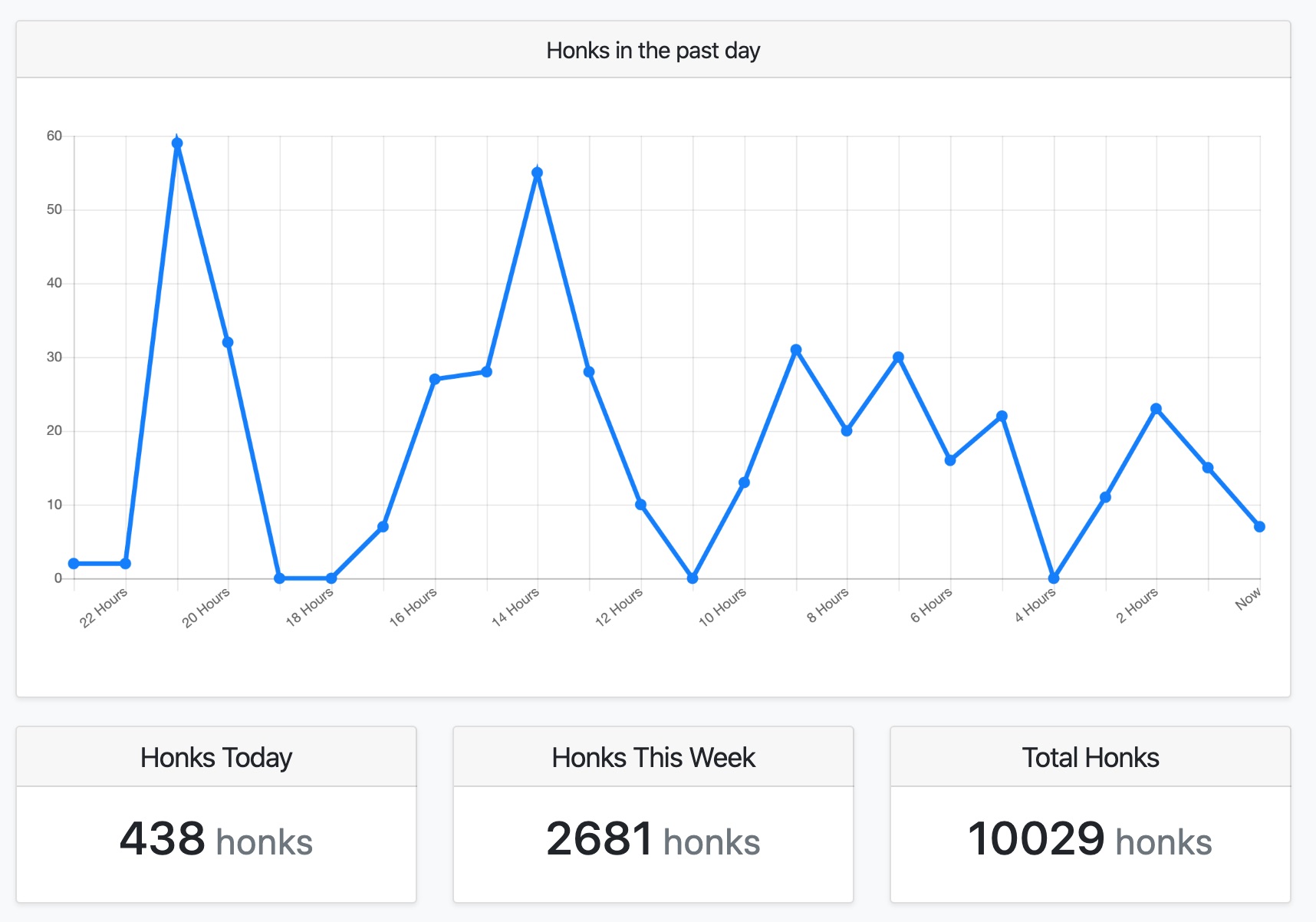
The final step is to push the data somewhere on the web, because why not. I used google app engine to create a simple website for displaying detections. At some point I will collect the data and do some analysis. It was surprising to see how much the train actually honks in a given 24 hour period. The site has only been alive for around three weeks and it just crossed 10,000 honks:
I was also obliged to make a twitter bot that posts every honk, this way if you really care, you can get push notifications immediately when the train honks. It's a surefire way to go crazy. (Don't) follow it here: @BywaterTrain