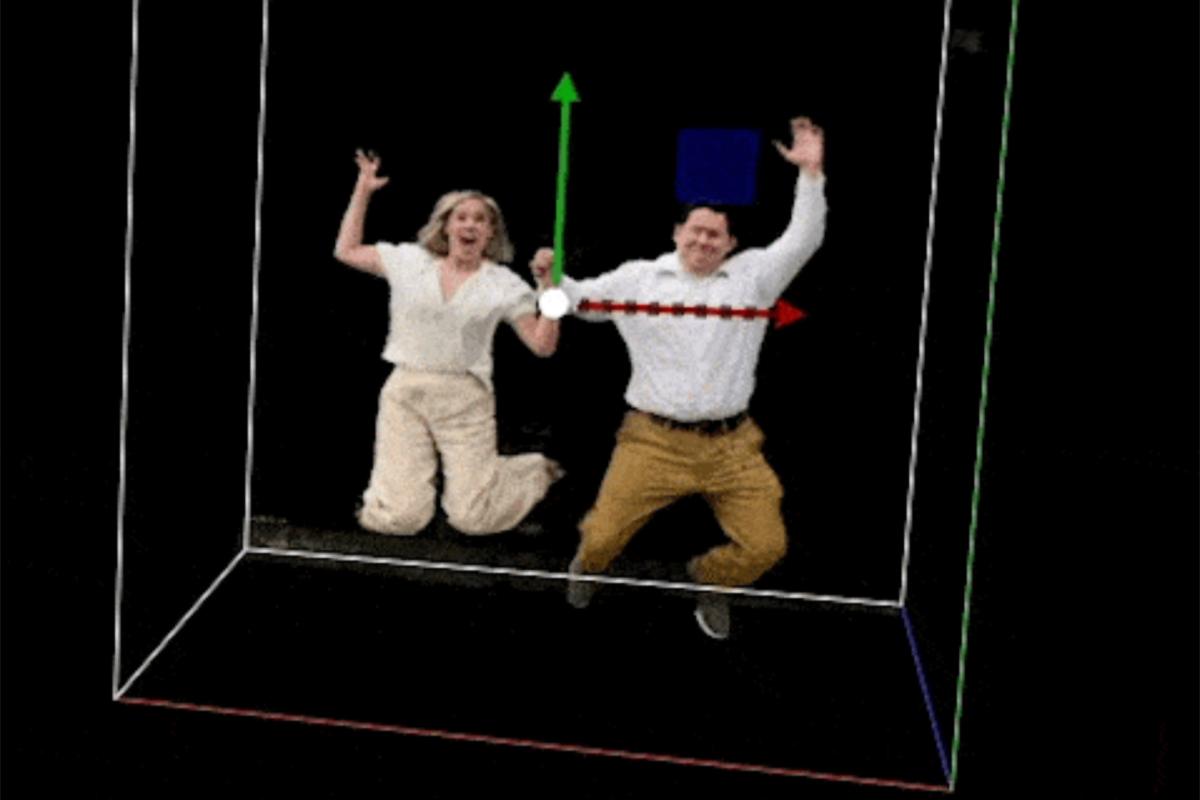
Slow Motion "Bullet Time" with NeRFs
Written by
Chris Laan
nerf, neural radiance fields, bullet time
January 2, 2023
We used NeRFs and 15 iPhones to Record Volumetric 3d "Bullet Time" Video

NeRF Bullet Time
Full Video
My cousin was getting married last month, and we were doing a family photo shoot for the occasion. I took the opportunity to revisit an idea we have been tinkering with for a while. The basic idea was: get a bunch of friends together to capture a scene from different angles using mobile phones. The end result would be a freeze frame or Bullet Time video as seen in the Matrix.
When we first played with the idea years ago, NeRFs didn't exist – so we didn't have a good way to perform high quality "view synthesis". 'View synthesis' here just means rendering images of a scene from viewpoints different than those that originally captured the scene.
NeRFs, aka Neural Radiance Fields, have rapidly come onto the scene as an amazing new method for view synthesis and 3d reconstruction.
Neural Radiance Fields are a method for representing and rendering 3D scenes using deep learning. The main idea behind NeRFs is to use a neural network to predict the radiance of a scene at each point in 3D space. Given a set of input images of a scene, the neural network learns to predict the 3D structure of the scene, as well as the surface reflectance and illumination at each point. The resulting representation is a continuous function that can be evaluated at any point in 3D space, allowing for highly realistic rendering of the scene from any viewpoint. NeRFs can produce high-quality and photo-realistic renders of complex 3D scenes, and have the potential to revolutionize the field of computer graphics.
The field is moving so quickly that new approaches and improvements are appearing almost daily.
You can read more about NeRFs here or read the original paper here, or watch some cool NeRF renders on YouTube.
In 2021, NVIDIA released Instant NGP – an open source toolkit for rapidly creating NeRFs from images or video. Instant NGP decreased NeRF training time from days to minutes.
Bullet time with NeRFs has been done before, and new NeRF extensions allow representing dynamic scenes by adding a time component to existing NeRF models. (see 'Dynamic Nerfs' such as DNerf)
Given that this was a fun / quick side project, I was not able to test out any of the newer approaches and opted for the ease of use and fast training times Instant NGP gives.
Nerfstudio is another NeRF training toolkit worth checking out. It even has support for "DNerf" for dynamic scenes, but I have not had a chance to test it yet.
The pace of research is moving so quickly around NeRFs that in a few months there will likely be better / faster methods for creating something like this.
The first requirement for the project is capturing slow motion videos of a scene from different angles. Newer iPhones can capture video at 240 frames per second at 1920x1080 resolution which is good enough to train the NeRF with.
After gathering up all our testing devices, and asking family members, we came up with 15 iPhones. (Though typically a NeRF scene would use more like 40 - 100 images.)
I then created a simple Firebase Realtime database app that allows me to start recording simultaneously on all phones. Once videos were captured, they were automatically uploaded to google cloud storage.
Pressing record on one phone starts recording on all connected devices.

Sync'd recording across phones
The app also shows the battery level and video upload status for each device:
We built some basic tripods out of cheap lumber and asked a few family members to hold the other phones:

Capture Setup with Tripod
Here are some of the captured images from the different phones:

Sample Images
The app did lock focus / exposure on recording, but did not sync those values across phones, so you can see some color differences in the images. More on that below.
We had a pretty short time window of maybe 10 minutes to setup and capture the scene. With more time I would probably test some different camera setups to see what works best.
Once we captured all the videos, we need to time sync them.
As a developer I wanted to automate this process even though manually syncing the videos was the faster option for only doing it once.
I ended up writing a small python script that does cross correlation on the audio streams to find the best time offset between two videos.
To make this more robust, we brought along two metal rods that we clanked together at the start of the recording.
Audio waveforms of two un-synced videos:

Audio Alignment
Cross Correlation shows a clear peak where the two signals have maximum alignment:
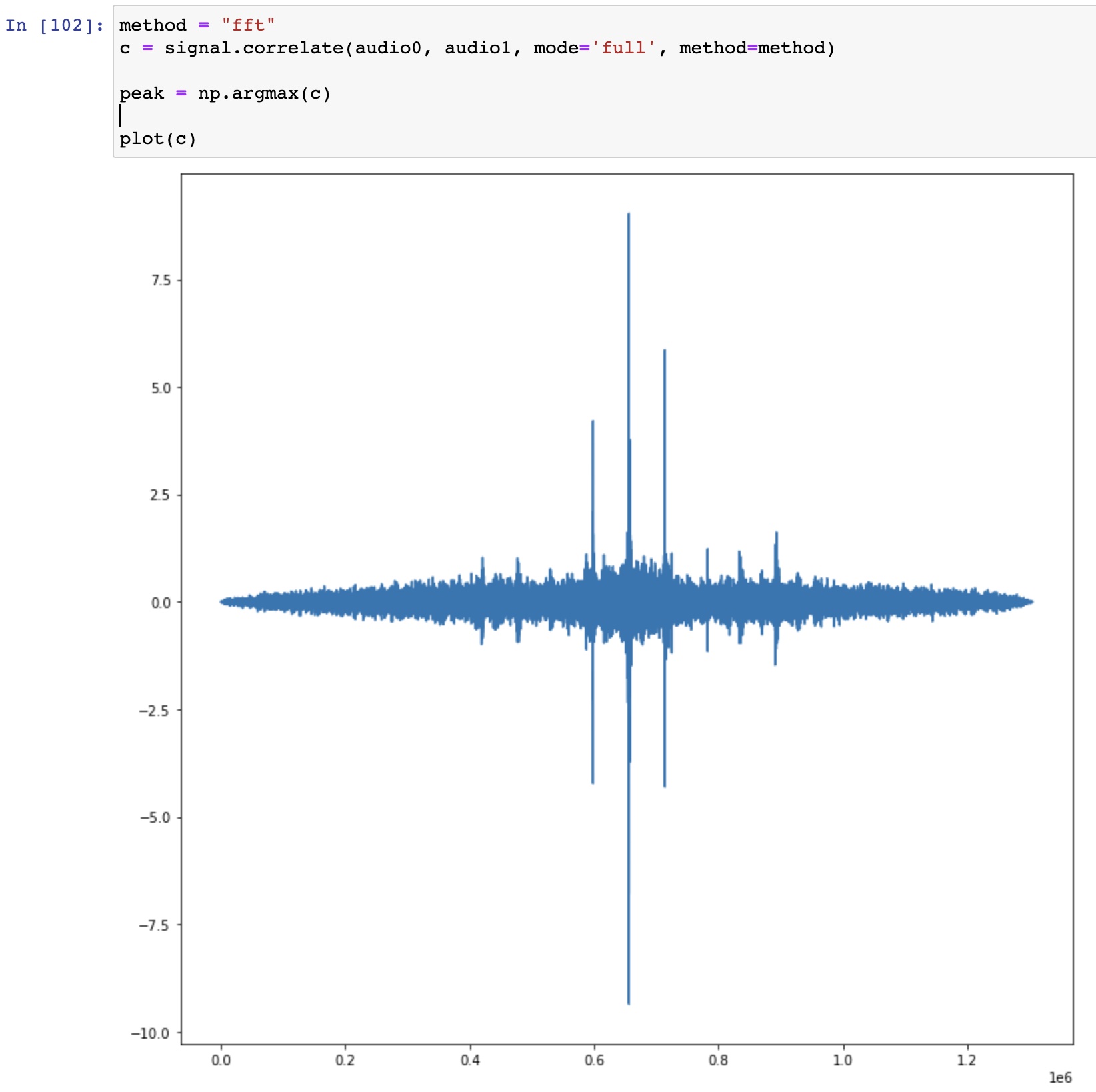
Cross Correlation
Once the videos were all aligned to the same global time, I exported a set of ~200 synced frames from all 15 phones. So about 3000 images.
The next step is training the NeRFs on all the data – a few issues came up here worth mentioning.
First some background on the NeRF training process:
The first step of NeRF is to compute camera poses for all images in the scene. COLMAP is used to do this
For the bullet time case we have as many "scenes" as there are timesteps in our exported videos (i.e. 200 timesteps)
So we need a way to make sure the camera poses are aligned into a global coordinate system that doesn't change throughout the video.
If all cameras do not move while capturing the scene, this is pretty simple: just compute the poses for the first frame and reuse those for all subsequent frames. For my case, we had people holding a few of the phones during the capture, and those phones moved slightly while filming.
With only 15 total cameras, I didn't want to lose the vital camera angles from the phones that moved slightly. This required computing camera poses for the dynamic cameras for each of the 200 timesteps.
Given the choice, next time I would opt for all static cameras on tripods since it really simplifies the pose recovery process.
I tried a few different approaches to this, but settled on customizing COLMAP slightly to allow for incremental scene reconstruction.
The approach I took starts with a "background" scene where the camera poses are computed once, and remain fixed while new images are added to it. The background scene was captured without people in it, so I was free to walk around with a single phone and capture lots of images.
Each "timestep" in the video has 15 images from all cameras recording. So for each timestep, we start with the background scene, then add new images into it while fixing the camera poses from the background scene. COLMAP has support for adding new images into an existing static scene using the "--Mapper.fix_existing_images" option, but unfortunately it still modifies the base camera poses during the bundle adjustment step, and further in the normalization step. I modified COLMAP to fix existing camera poses in the bundle adjustment steps, and not normalize the scene when the "fix_existing_images" option is passed.
The next issue that came up was that with only 15 cameras, the resulting trained NeRF only represented a pretty small 3d volume around the subject (people). Moving the camera to show different parts of the scene resulted in lots of artifacts / floaters:

Sample Frame with Floaters
So in order to render the other parts of the scene, I captured about 200 images of the surrounding area without any people in it.
I then trained up a separate NeRF which would be composited with the NeRF for each timestep:

Background Scene NeRF Render
As mentioned above, my custom COLMAP setup meant that the background NeRF was already in the same coordinate system as each of the timestep NeRFs, so the different renderings perfectly composite together when rendering camera paths:

Scene Composite
Though I had to render the dynamic NeRFs with a cropping volume and transparency to make sure only the people were rendered:

Foreground Crop Volume
Some notes around quality / rendering issues that came up during the project.
I originally trained each NeRF timestep separately, but when creating the animation from all the NeRFs, there was a lot of flickering artifacts:

Time Flickering
I tested out re-using the trained network from a previous timestep as the initialization for the subsequent timestep (specifically saving a snapshot after about 500 steps to be used as the init for the next timestep)
This definitely improved the continuity of the solution that the network settled on to be similar across timesteps. If I had more cameras I don't think this would be as big of an issue since there is less room for ambiguity in the scene.
Artifacts referred to as floaters come up when there is ambiguity in the views during training. Adding more camera views reduces this, but for our case adding more cameras is not easy for the dynamic scene.
Tuning the training "near distance" definitely helped reduce floaters. I came close to implementing a per camera near distance in order to further reduce floaters.
Another idea I was considering building was masking volumes or planes. The basic intuition is: "I know there's empty space here, so don't put any floaters / density here"
An example is the floor / ground plane. For scenes with an obvious floor plane such as this one, if I could set it such that no density would be allowed under the floor plane, the reconstruction of the ground would appear more consistent for novel views.
The same goes for large volumes of empty space – NeRF will often learn density in areas where it would be easy to draw a giant cube volume to "zero out" any gradients there.
I also wanted to test out some depth supervision to see if that would reduce floaters too.
Regularization has been incorporated into many follow up NeRF methods, but not much afaik into the Instant NGP repo. With more time I would like to explore some techniques to nudge the network training in the right direction.
In the end, using the clean background scene trained on lots of views along with the masked people meant floaters were not a big issue.
If you have limited camera angles, these ideas might become worth exploring.
Some frames captured from different phones have slightly different color tones:

Color Tone Mismatch
Including a calibration marker in the images might make automatically solving this a bit easier. There are probably lots of ways to solve or improve this issue. Perhaps on the capture side we could sync white balance / exposure across all phones. I did not explore other techniques to solve this issue.
One idea was to select the same points across images, and then solve for a color transformation operation that reduces the color differences across images.
An issue might be not hitting exactly the right pixel across the same images.
Using SIFT features from COLMAP might help, but since SIFT features often lie on edges / high contrast, we might end up selecting different colors for the "same" 3d point projected into different images.
The first and only thing I tried to solve this issue was optimal transport of color histograms.
I found some nice code examples on the web from the Python Optimal Transport / POT library here:
https://pythonot.github.io/auto_examples/domain-adaptation/plot_otda_mapping_colors_images.html#sphx-glr-auto-examples-domain-adaptation-plot-otda-mapping-colors-images-py
My only slightly clever modification was to sample more heavily on the people in the image, since that's what I care about most, but also the people are in every shot.
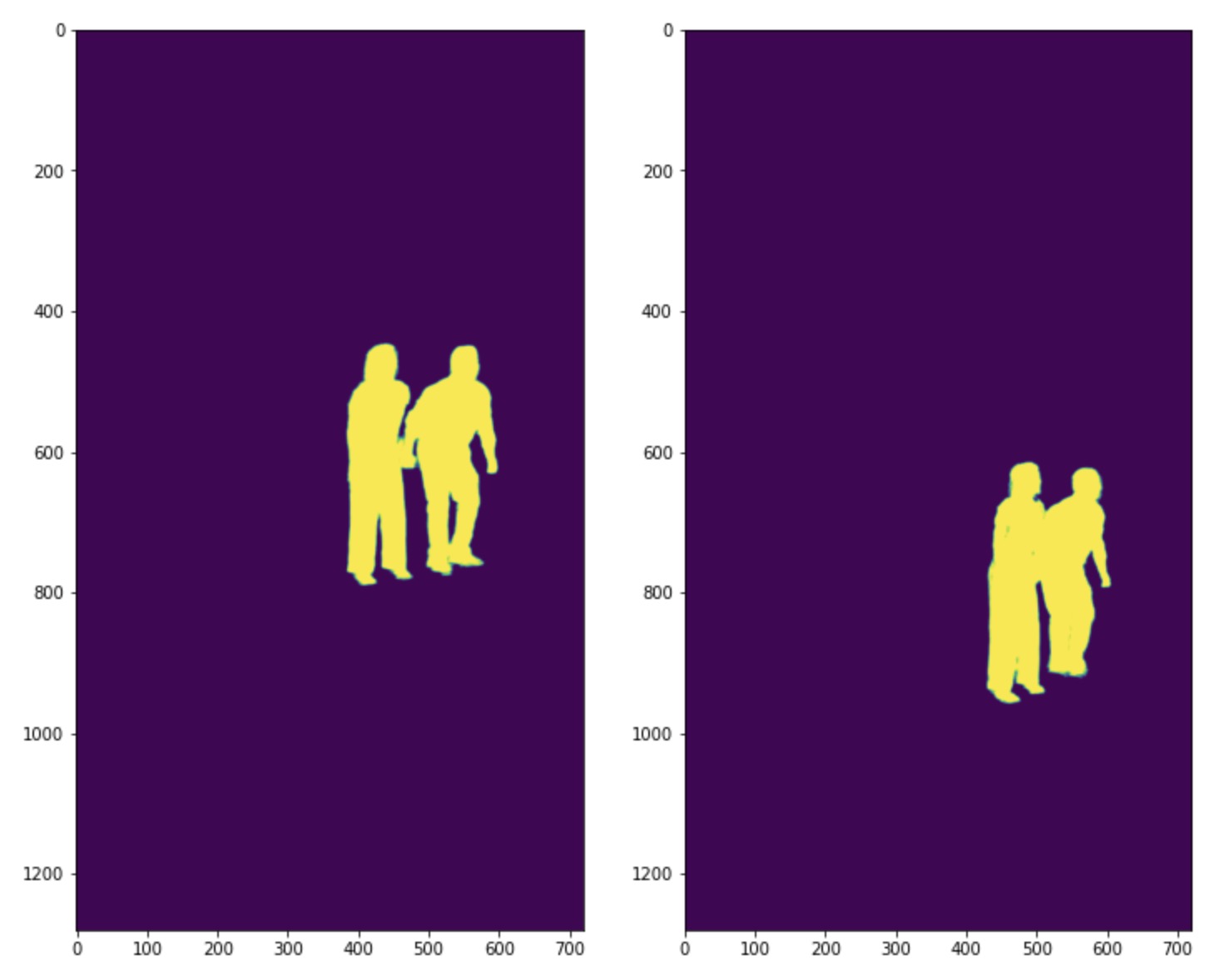
Person Segmentation Masks
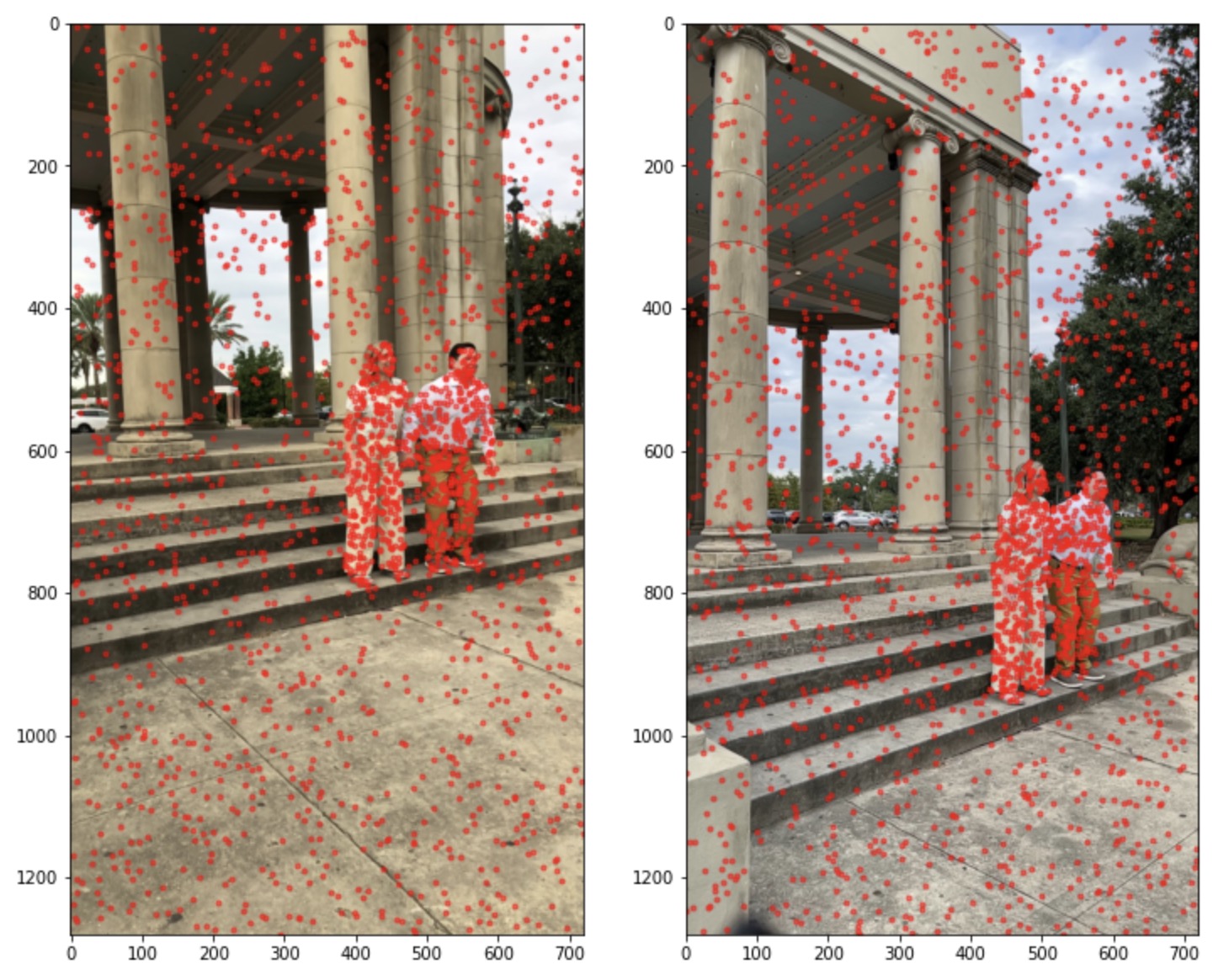
Person Segmentation Sampling
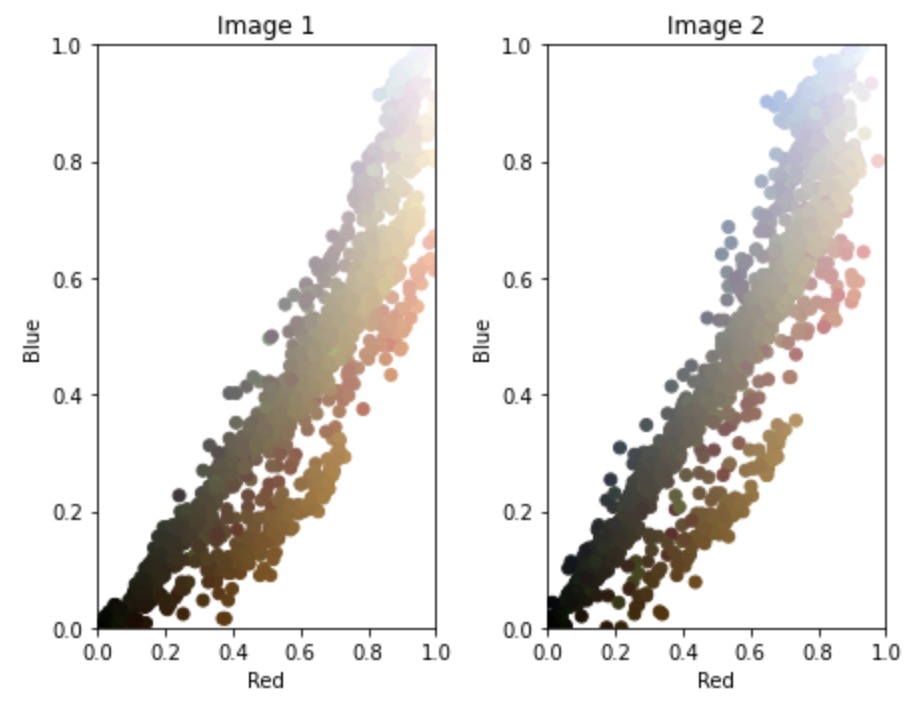
Color Plots
It's subtle change, but I think it makes a difference in the NeRF reconstruction:

Matched Images

Matched Images Animation
If you are interested in building on this email us
If you need help using NeRF for a project, send us an email.
Get the markdown source for offline reading