The Challenge: Documentation at Scale with RID
Every industry faces the same fundamental challenge: how do you rapidly document, inspect, and share information about physical assets? Whether it's an insurance adjuster assessing damage, an engineer inspecting aircraft parts, or a film crew planning a shoot, the questions remain constant: Where is it? What is it? What condition is it in?
Traditional documentation methods are painfully slow, prone to human error, and create silos of information that are difficult to share. Inspectors typically capture hundreds of photos, manually write reports, and rely on memory to connect observations across multiple visits. Critical details get missed, handwritten notes become illegible, and sharing findings with remote teams requires hours of report compilation.
We've spent over years working in AR/VR/XR, watching the technology evolve from experimental to essential. Now, with the convergence of mobile computing power, computer vision, spatial computing platforms like Apple Vision Pro, and modern multimodal AI, we're finally able to deliver on the promise of Rapid Inspection & Documentation (RID).
Laan Labs is transforming asset documentation across industries using spatial computing and AI—from aerospace parts inspection to insurance claims, making comprehensive documentation accessible to everyone.
What is RID?
RID (Rapid Inspection & Documentation) is our systematic approach to capturing, storing, and collaborating on physical asset information. Born from years of experience building computer vision and AR applications used by millions, RID represents the culmination of advances in mobile sensors, spatial computing, and artificial intelligence.
The Evolution of RID
Traditional inspection workflows were fragmented: capture photos, manually transcribe serial numbers, write separate reports, and hope nothing was missed. RID unifies this into a single, intelligent workflow where AI does the heavy lifting.
It's not just about taking photos—it's about creating a comprehensive, AI-enhanced digital twin that combines:
- High-resolution 2D images with 3D positional data: Capturing spatial context automatically
- Automated text extraction and OCR: Reading serial numbers, labels, and signage even in challenging conditions
- Multi-modal LLM analysis: Modern vision-language models that can understand images, identify defects, and generate detailed reports
- Immersive XR review capabilities: Review and collaborate in spatial computing environments
The RID Advantage
What makes RID transformative is the integration of modern multimodal Large Language Models. These AI systems can:
- Identify parts and components from images without pre-training on specific assets
- Detect defects, corrosion, damage, and wear patterns
- Extract and aggregate text from multiple angles (solving the partial OCR problem)
- Generate comprehensive inspection reports in natural language
- Answer questions about asset conditions using visual evidence
- Compare current state against historical documentation
The beauty of RID is its versatility. We're seeing adoption across industries:
- Architecture & Planning: Creating digital twins and renovation plans
- Manufacturing: Documenting equipment conditions
- Insurance: Claims documentation and facility reviews
- Film & VFX: Production planning and previsualization
- Real Estate: Virtual tours and property management
- Shipping & Logistics: Cargo management and quoting
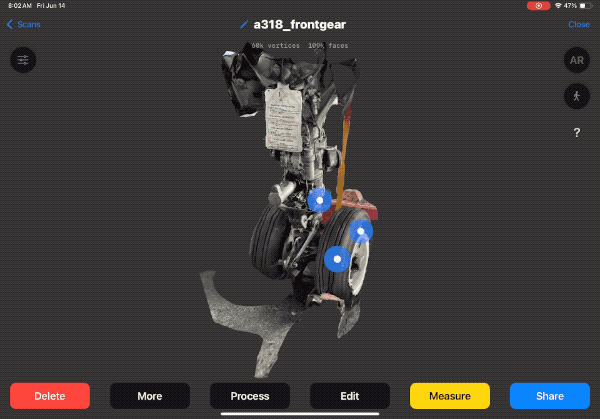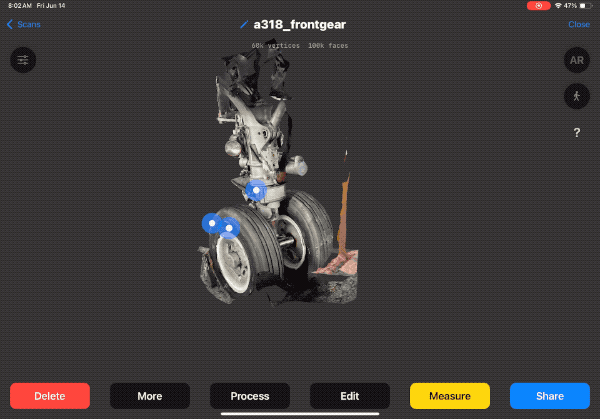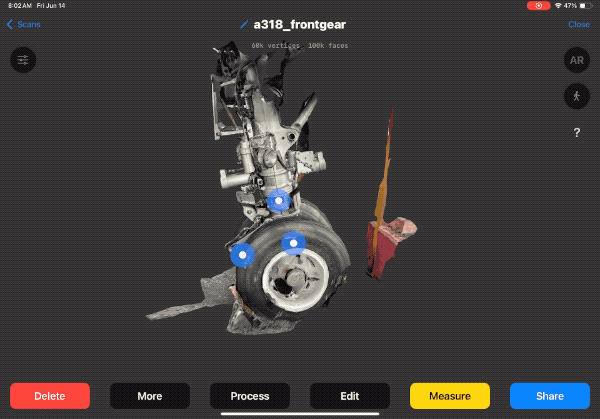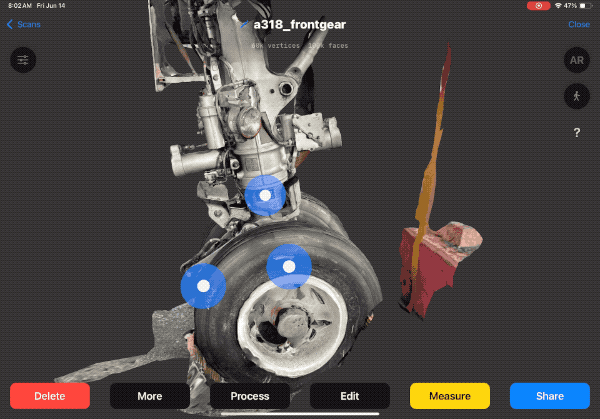
Case Study: Aerospace Parts Documentation
To demonstrate RID's capabilities, let's look at a recent project documenting end-of-life aerospace parts for reuse—specifically, landing gear from the Airbus A318.
The Challenge
The A318 had limited production (only ~80 aircraft built from 2001-2013), but about 60 remain in service, creating ongoing demand for replacement parts. The challenge: how do you continuously document the condition of complex parts while the aircraft is still in service, ensuring accurate information for future reuse?
Our Solution
Using just an iPhone with LiDAR capabilities, field technicians can now:
- Capture Ground Truth Data: Create comprehensive datasets including RGB images with pose data, depth information, GPS coordinates, and field annotations
- Real-time 3D Reconstruction: Generate accurate 3D models from 2D images on-device
- AI-Powered Visual Inspection: Modern LLMs analyze images to:
- Identify part numbers and serial codes from any angle, even when partially obscured
- Detect surface defects, corrosion, cracks, and wear patterns
- Assess component condition and flag potential safety concerns
- Generate detailed inspection reports automatically
- Intelligent OCR & Text Aggregation: Our multi-modal LLM integration excels at handling partial text and aggregating information from multiple angles—solving traditional computer vision challenges that stumped earlier OCR systems
- Surface Notation: Mark specific areas for review or collaboration directly on 3D models
- Conversational Analysis: Ask questions about the asset ("Show me all hydraulic components" or "What's the condition of the brake assembly?") and get AI-powered answers grounded in captured visual data
The result? What once took days of manual documentation now happens in minutes, with far greater accuracy, consistency, and detail.
Modern LLMs: The Intelligence Behind RID
The breakthrough in RID's capabilities comes from integrating state-of-the-art multimodal Large Language Models that can analyze images with human-level (and sometimes superhuman) accuracy. Our platform leverages multiple LLM providers to optimize for different inspection scenarios:
Vision-Language Models in Production
Our RID platform integrates state-of-the-art multimodal models from leading AI providers including OpenAI, Anthropic Claude, and Google Gemini, enabling capabilities such as:
- Complex reasoning about visual defects and anomalies
- Multi-image comparison for detecting changes over time
- Generating detailed, context-aware inspection reports
- Understanding spatial relationships between components
- Exceptional accuracy in technical documentation analysis
- Superior performance on partial text extraction from challenging angles
- Comprehensive report generation with structured outputs
Custom Fine-Tuned Models
Beyond these foundation models, we've developed specialized variants:
Defect Detection Models: Fine-tuned on industry-specific datasets to identify:
- Corrosion patterns in aerospace components
- Structural damage in buildings and infrastructure
- Wear indicators in mechanical systems
- Surface finish quality in manufacturing
Part Identification Models: Custom-trained to recognize:
- Specific aircraft components and assemblies
- Manufacturing equipment and tooling
- Building systems and HVAC components
- Vehicle parts and assemblies
OCR Enhancement Models: Specialized for:
- Reading degraded or damaged serial numbers
- Extracting text from curved or reflective surfaces
- Aggregating partial text fragments across multiple images
- Handling poor lighting and challenging capture conditions
The Multi-Model Approach
Our RID platform intelligently routes inspection tasks to the most appropriate AI model based on the specific use case, whether it's critical safety inspections requiring maximum accuracy, high-volume documentation needing fast processing, specialized detection with custom fine-tuned models, or real-time field analysis for immediate feedback to technicians.
This flexibility ensures optimal performance, cost, and accuracy for each scenario. Users can also manually select their preferred model based on specific requirements or compliance needs.
Practical Impact
The integration of these LLMs transforms inspection workflows:
- Automated Report Generation: What took hours of manual writing now happens in seconds, with comprehensive analysis backed by visual evidence
- Consistency: AI models apply the same rigorous analysis to every inspection, eliminating subjective variation
- Accessibility: Non-experts can perform detailed technical inspections with AI guidance
- Continuous Learning: Models improve over time as they process more domain-specific data
The Technical Stack
Our RID pipeline leverages cutting-edge technologies across the entire workflow:
- Mobile Capture: iOS devices with LiDAR for depth sensing and pose tracking
- Computer Vision: Custom ML models for object detection, scene analysis, and spatial reconstruction
- Multi-Modal LLM Integration:
- OpenAI models for vision-language understanding
- Anthropic Claude for technical analysis
- Google Gemini for high-volume processing
- Custom fine-tuned models for domain-specific inspection tasks
- Spatial Computing: Apple Vision Pro for immersive review and collaboration
- Cloud Processing: Scalable backend for Gaussian Splat generation, 3D reconstruction, and distributed AI inference
- Database & Storage: Optimized for spatial data, versioning, and collaborative workflows
Apple Vision Pro: A Game Changer for Remote Collaboration
The Apple Vision Pro has transformed how remote teams collaborate on physical assets. Engineers can now review parts in high fidelity from anywhere in the world, with the device's exceptional resolution providing unprecedented detail for inspection tasks.
Combined with our LLM-powered analysis, teams can:
- View 3D reconstructions with AI-generated annotations highlighting areas of concern
- Ask natural language questions about asset conditions while immersed in the spatial model
- Review AI-generated inspection reports alongside the actual 3D geometry
- Collaborate with remote team members who see the same AI insights in real-time
We've even built AirDraw, a spatial drawing app that showcases these capabilities and helps users understand the potential of spatial computing for creative and technical applications.
Looking Forward
RID represents more than just a technical achievement—it's a fundamental shift in how organizations think about physical asset documentation. By combining the ubiquity of mobile devices with the power of spatial computing and AI, we're making comprehensive documentation accessible to everyone.
The convergence of technologies we're seeing today—improved mobile sensors, powerful on-device processing, cloud-based AI, and immersive displays—is creating opportunities we could only dream about a few years ago. As these technologies continue to evolve, we're committed to pushing the boundaries of what's possible in spatial computing and computer vision.
About This Project
This work represents the culmination of over two decades of experience in XR and spatial computing. With 70+ million app downloads and multiple #1 rankings on the App Store (including apps like 3D Scanner App, Face Swap Live, and iVideoCamera), we've learned what it takes to make complex technology accessible and useful.
Want to learn more about how RID could transform your documentation workflows? Contact us at labs@laan.com or visit laan.com.
Technologies Utilized
Computer Vision, Neural Networks, LLM Integration, Spatial Computing, Apple Vision Pro, Mobile LiDAR, Gaussian Splatting, OCR, Cloud Services